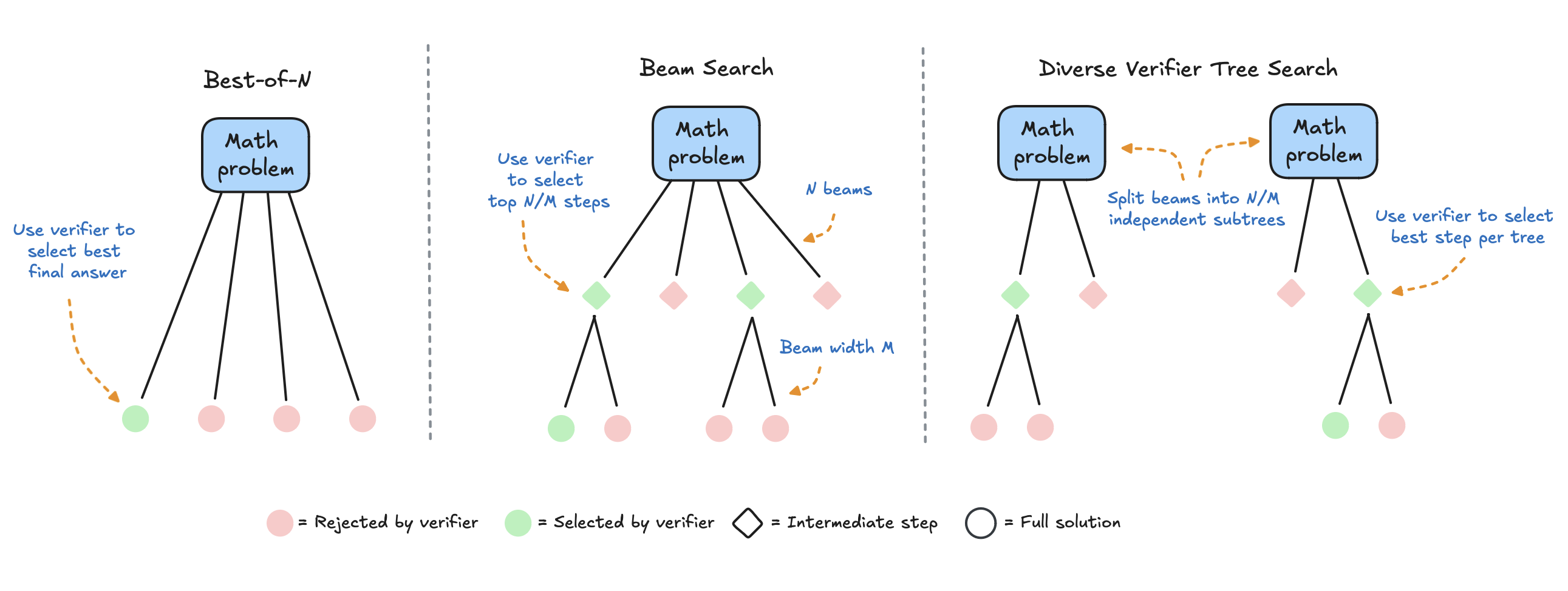
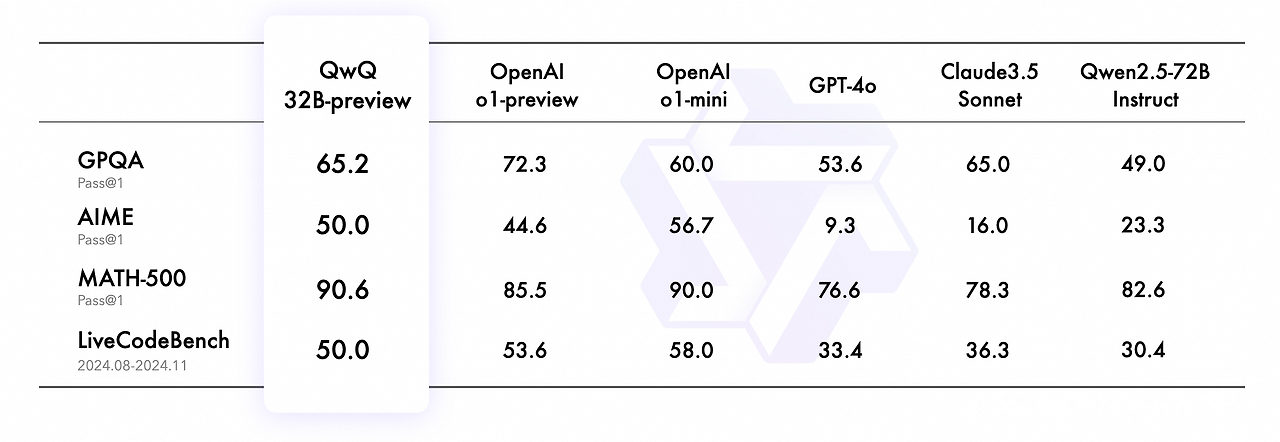
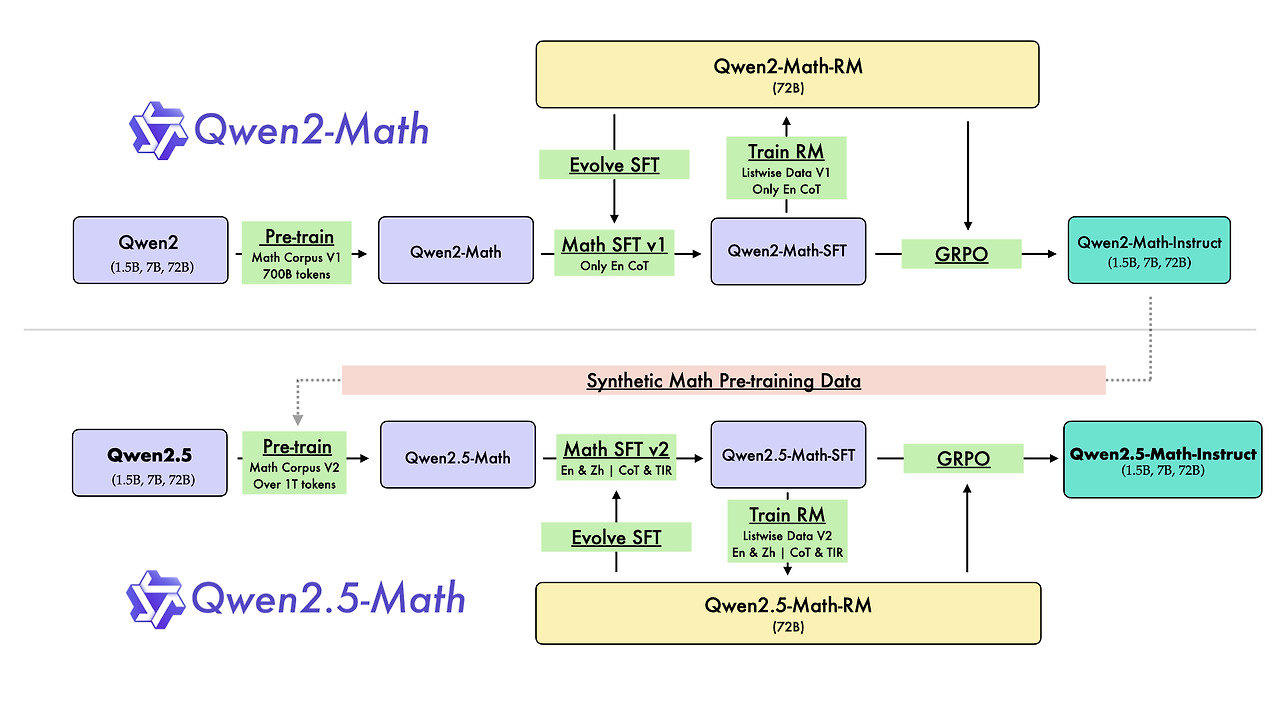
노트북 환경과 데스크탑 환경을 동일하게 C++ 개발환경을 VS Code + mingw으로 구축했다. 하지만 왜인지 노트북에서는 Code Runner를 활용해서, C++ exe를 실행할 때 출력, 에러 아무것도 일어나지 않는 문제가 발생했다. 오류코드라도 나면 모르겠는데, 해결하기가 너무 어려웠다. 맘먹고 오류를 해결해보고자, Stack Overflow에서 동일한 증상을 찾기 시작했다. 오류 파악 원인1: CMD 환경에서의 테스트Code Runner Extension은 C++ 프로그램을 실행할 때, g++examp≤.cpp-oexamp≤&&.examp≤ 명령어로 g++로 컴파일을 진행한 뒤, 해당 파일을 실행한다. 나는 VS Code 내부 터미널에서 실행하고자, 'Run In Termi..