목차
시작
2017년 구글에서 발표한 "Attention Is All You Need"라는 공격적인 이름의 논문이다. 현재는 시기도 오래 지난 논문이지만, 아직까지 Attention이 전부인가?라고 묻는다면, 단연 아직도 "Yes."로 대답할 것이다.
논문을 읽어보고, 한 번도 글로 정리했던 적은 없었던 것 같아, 한참 늦었지만 시간이 비었을 때 내 생각을 정리하려고 한다. 자, 시작해 보자. 2024년에 읽는 Transformer 논문.
여담으로, 아직도 Attention이 전부인가를 표시해주는 사이트가 있다..
개요와 배경
회귀 모델의 문제점
순차적 모델링과 기계 독해, 언어 모델링과 같은 Transduction 문제(한국어로 해석하기가 힘들다)에서 RNN, LSTM, GRU, Encoder-Decoder와 같은 구조가 좋은 성능을 내고 있었다.
하지만, 이런 회귀 모델들은 이전 타임스탭의 출력을 다음 타임스탭의 출력에 이용하는 순차적인 문제점이 있다.
이러한 특성으로, 훈련과정에서 병렬 처리가 불가능해지고, 따라서 더 긴 시퀀스길이에서 치명적으로 작용할 것이다.
Attention
Attention 방법론은 입력 또는 출력의 거리와 상관없이 의존성을 모델링할 수 있기 때문에 다양한 작업에서 순차모델, Transduction 모델에서 필수적인 부분이 되었지만, 일부를 제외하고는 회귀 모델과 대부분 함께 사용되고 있다.
Transformer구조의 제안
따라서, 회귀를 제외하고, 전적으로 Attention만 사용해서 입력과 출력사이에 전역적인 의존성을 이끌어내도록 하는 Transformer구조를 제안했다.
배경
Multi-Head Attention
순차적인 연산을 줄이도록 하는 기존의 노력(Extended Neural GPU, ByteNet, ConvS2S 등)이 있었지만, 이들은 기본적으로 Convolution을 사용해서 모든 입력과 출력에 대한 Hidden States를 병렬로 계산했다.
따라서, 임의의 두 개의 입력 또는 출력을 연관 짓기 위해서는 연산 수가 위치 간의 거리에 따라서 증가하고, ConvS2S는 Linear하게, ByteNet은 Log적으로 증가했다. 이 것이 먼 위치간의 거리에 따른 의존성을 학습하는데 어렵게 만들었다.
Transformer에서는 이 것을 상수로 줄였지만, Attention 가중치를 사용한 위치의 평균화로, 효과를 미치는 resolution이 감소하는 대가를 치렀다. 이 문제를 해결하기 위해서, "Multi-Head Attention"으로 대처하는 노력을 함.
두 모델(ConvS2S, ByteNet)의 구조를 정확히 몰라서, 자세하게 얘기하긴 힘들다.
하지만, Convolution을 사용하는 대부분의 모델들은 Stride간격으로 계산하는 방향으로 구현하니까 시퀀스에서 거리가 멀다면, 그 과정에서 연산이 늘어난 것 아닐까 하는 추측.
Self-Attention
Self-Attention은 시퀀스의 representation을 계산하기 위해, 단일 시퀀스에서 서로 다른 위치를 연결하는 방법이다. 요약, 독해, 텍스트기반 추론 등 다양한 작업에서 성공적으로 사용되고 있다.
End-to-end Memory Networks
End-to-end Memory Network는 시퀀스 정렬 회귀 대신, Attention 기반의 회귀를 사용한다. 이 모델은 간단한 질문-응답, 언어 모델링 작업에서 좋은 성능을 냈다.
구조

Transformer는 그 당시에 좋은 성능을 보였던 Encoder-Decoder구조를 동일하게 따른다. 위의 그림에서 왼쪽은 Encoder, 오른쪽은 Decoder이다.
Encoder는 Symbol 표현들의 입력(x1,...,xn)을, 시퀀스의 연속적인 표현(z=(z1,...,zn))으로 맵핑하고, Decoder는 z를 가지고, 새로운 심볼 시퀀스 아웃풋(y1,...yn)을 한 차례에 하나씩 만든다. 각 스텝별로 모델은 Auto-Regressive하게, 이전에 생성한 심볼을 새로운 입력으로 하여, 다음 차례의 출력을 만드는 데 사용된다.
이제 Transformer 구조에서의 Encoder와 Decoder는 어떻게 구성되어 있는지 자세히 살펴보자.
Encoder
Transformer의 Encoder는 2개의 Sub-Layer로 구성된, Layer를 N=6개 쌓은 구조이다.
각 Sub-Layer는 "Multi-Head Attention" 과 "Position-wise Fully connected feed-forward" 로 구성되어 있다. 또한, Sub-Layer의 출력에는 Layer Normalization 후, Residual Connection(잔차연결)을 사용했다. 저자는 Residual Connection의 편리성을 위해서, 모든 Sub-Layer와, 임베딩 레이어는 출력을 dmodel=512로 고정했다.
Decoder
Decoder는 3개의 Sub-Layer로 구성된, Layer를 N=6개 쌓아서 구성했다. 큰 구조는 Encoder와 비슷해 보이지만, 특이한 점은 가운데 Encoder의 출력을 받는 Multi-Head Attention이 존재한다. 또한, Encoder와 동일하게, 각 Sub-Layer에 Residual Connection을 적용하고, Layer Normalization을 적용했다.
또,또한, Decoder의 Self-Attention Sub-Layer에는 이후 위치에 대한 내용을 반영하지 않도록, 수정했다. 따라서, 이 마스킹을 통해,i번째 위치에 대한 출력을 할 때, i보다 작은 출력만을 사용할 수 있도록 보장한다.
이제 더 깊게 들어가서, Attention의 구조를 살펴보자.
Attention
기본적으로, Attention 함수는 Query와 Key-Value 쌍을 출력 벡터에 맵핑하는 것이다. 이 출력은 Query와 그에 상응되는 Key에 의해 가중합으로 계산된다.
Scaled Dot-Product Attention
여기서는 Attention으로, Scaled Dot-Product Attention 형태를 제시한다. 여기서 사용되는 몇 가지 파라미터 값이 있다.
- dk : Query와 Key의 Dimension
- dv : Value의 Dimension
그림을 통해 Attention이 적용되는 과정을 파악할 수 있다. 과정을 식으로 구체화한다면, 다음과 같이 표현할 수 있다.
Attention(Q,K,V)=softmax(QKT√dk)V
이전 Attention의 관한 논문들을 못 읽어봤어서, 잘 몰랐는데 일반적으로 많이 사용하는게 덧셈형태(
"Additive")와 dot-product(곱셈형태)가 있다고 쓰여있다. 이 논문에서의 기존과의 차이점이라면, 스케일링 팩터가 다르다는 것이다.
두 가지 방법의 복잡도는 이론적으로 비슷하지만, dot-product Attention 방법이 행렬곱셈 코드에 최적화해서 사용하여 구현할 수 있기 때문에, 훨씬 빠르고, 공간효율적이라고 한다.
또한, 작은 스케일링 팩터 dk에선 두 방법이 비슷한 성능을 내지만, 큰 값에서는 덧셈형태의 Attention이 곱셈형태를 능가한다고 한다. 그 이유로는 Softmax 함수의 Gradient를 아주 작게 만들어버리기 때문일 것으로 의심된다고 한다. 따라서 스케일링 팩터로 √dk를 사용한다.
Multi-Head Attention
단일차원의 dmodel로 Query, Key, Value모델을 사용하는 것보다, dk(Query, Key) dv(Value)의 차원으로 학습된 것을 h번 Linear하게 프로젝션 하는 게 더 좋다는 것을 발견했다. 따라서, 각 Attention을 병렬로 수행해서, dv차원의 출력을 생성하고, 이 값들을 이어 붙이고, Linear 모델의 최종 출력을 얻는다.
이를 통해서, Multi-Head Attention은 다른 표현공간들에서 정보들에 깊게 살펴볼 수 있게 만든다. (single이면 못했을 것, 평균을 내버려서 못했을 것!)
수식으로 표현하면, 다음과 같다.MultiHead(Q,K,V)=Concat(head1,...,headn)WOwhere headi=Attention(QWQi,KWKi,VWVi)프로젝션의 파라미터는 다음과 같이 차원을 갖는다.
WQi∈Rdmodel×dkWKi∈Rdmodel×dkWVi∈Rdmodel×dvWO∈Rhdv×dmodel
이 논문에선, h=8, dk=dv=dmodel/h=64를 사용한다. 각 head의 차원을 줄임으로써, 단일 헤드 Attention을 사용할 때와 컴퓨팅 비용은 비슷하다고 한다.
Position-wise Feed-Forward Networks
이제 Attention에 너무 Attention해버려서? 까먹었을 수 있겠지만, Sub-Layer의 뒷단에 붙어있는 Feed-Forward Network에 대해서 살펴보자.
FFN(x)=max(0,xW1+b1)W2+b2
간단하게, 두 개의 선형변환사이에 ReLU 활성화함수가 포함된 형태이다. 입력과 출력은 dmodel=512차원이고, 내부레이어의 차원은 dff=2048차원이다.
Embedding과 Softmax
다른 Transduction 모델과 동일하게, 입력 토큰, 출력 토큰에 대한 벡터를 dmodel 차원으로 변환해 주는 임베딩을 포함해서 학습했다. 또한, Decoder의 출력을 다음 토큰 예측을 위한 확률로 사용하기 위한, 선형변환과, Softmax함수도 학습에 포함했다. 임베딩 레이어와 Softmax이전의 선형 변환에서 사용하는 가중치를 공유한다. Embedding Layer에서는 가중치에 √dmodel을 곱한다.
Positional Encoding
Encoder와 Decoder에서 Embedding 이후에 가장 먼저 접하는 Positional Encoding이다.
Transformer는 회귀나, Convolution같은 모델이 시퀀스의 순서를 활용할 수 있게 만드는 부분이 없다. 따라서 위치에 대한 정보를 주입할 필요가 있다. Positional Encoding에는 다양한 방법이 있지만, 여기서는, sin과 cos함수를 이용한다.
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
pos은 토큰의 위치이고, i는 차원이다. 함수를 통해 위치정보를 얻을 수 있는 것에 대해서 살펴보자.
- 두 함수는 짝수 차원에선 sin 함수를 홀수 차원에선 cos함수를 사용했다.
- 차원에 따라, 함수의 파장이 2π ~ 10000⋅2π이 될 수 있다.
- 토큰의 위치에 따라 -1 ~ 1의 값으로 변한다.
Positional Encoding은 dmodel의 차원을 갖게 되면서, 임베딩에 더해줌으로써, 쉽게 위치정보를 주입할 수 있다. 또한, 학습이 필요 없으면서, 다양한 방법으로 토큰의 위치에 따른 값을 주입하기에, 효율적인 측면이 분명 있을 것이라 생각한다. (성능 또한 학습시킨 Positional Encoding과 거의 차이가 없었다고 한다.)
왜 Self-Attention을 선택해야 하는데?
Transformer의 구조에 대한 설명을 마치고, 이제 Self-Attention의 장점들을 정리해 보자.
- 각 레이어의 전체 컴퓨팅 복잡도
- 병렬화할 수 있는 최소로 필요한 Sequntial 연산의 양
- 네트워크의 장기 의존성 경로의 길이
이 중 네트워크의 장기 의존성 경로의 길이에 대한 내용을 자세히 살펴보자. 아래 표는 다양한 레이어의 최대 경로 길이에 대한 복잡도다. n은 Sequence의 길이, d는 Representation 차원, k는 Convolution에서 커널 사이즈, r은 Self-Attention의 제한된 이웃의 사이즈를 의미한다.

먼저, 이 논문에서 Computing 복잡도 측면에서 시퀀스 길이인 n이 Representation 차원 d보다 작을 때(당시 기계번역 SOTA 모델인 word-piece, byte-pair 등), 회귀모델보다 빠르다고 한다. 위의 표를 회귀모델은 O(n⋅d2)이고, Self-Attention 모델은 O(n2⋅d)이기에, n의 영향력이 Self-Attention에서 더 크기 때문일 것이다.
또한 아주 긴 길이의 시퀀스에서(n이 아주 클 때), r만큼 거리의 이웃만 고려하도록 제한하는 방식으로, Computing 복잡도를 개선할 수 있을 것이라고 한다. 하지만, 이 방식은 Max-Path Length를 O(n/r)로 증가시킬 수 있다고 한다.
Conv 레이어의 효율성도 언급이 되어있는데, 커널 크기(k)가 시퀀스 길이(n)보다 작을 때와, 동일할 때 효율성을 비교하는 내용도 나와있으나, 이 부분에 대한 내용은 여기까지만 다루도록 하자.
모델학습과 결과
학습방법에 대해선 특이한 부분은 없으니, 모델의 성능에 주목하자. 학습에는 기계번역에 관한 데이터셋으로 학습했고, 따라서 지표도 BLEU스코어를 사용해서 평가했다.
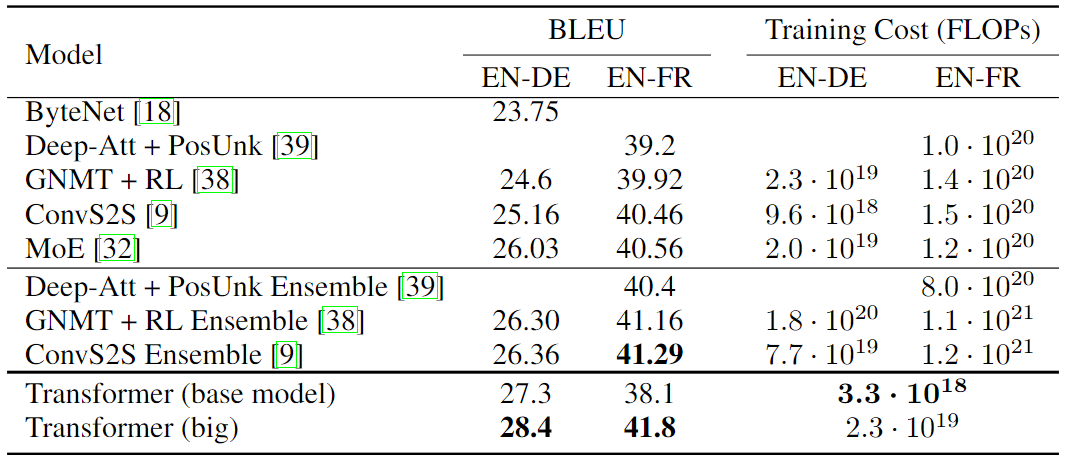
결과를 보면, 기존 모델들에 비해서 base model은 성능의 차이가 별로 없다 생각할 수 있는데, 훈련 비용면에서 아주 큰 차이가 나는 것을 볼 수 있다. 또한 big model의 경우, 앙상블 모델을 포함해서도 지표가 가장 좋은 것을 볼 수 있다.
또한, 영어-독일어 번역 데이터셋에 대해서, 다양한 변형으로 모델 성능을 테스트한 결과는 다음과 같다.
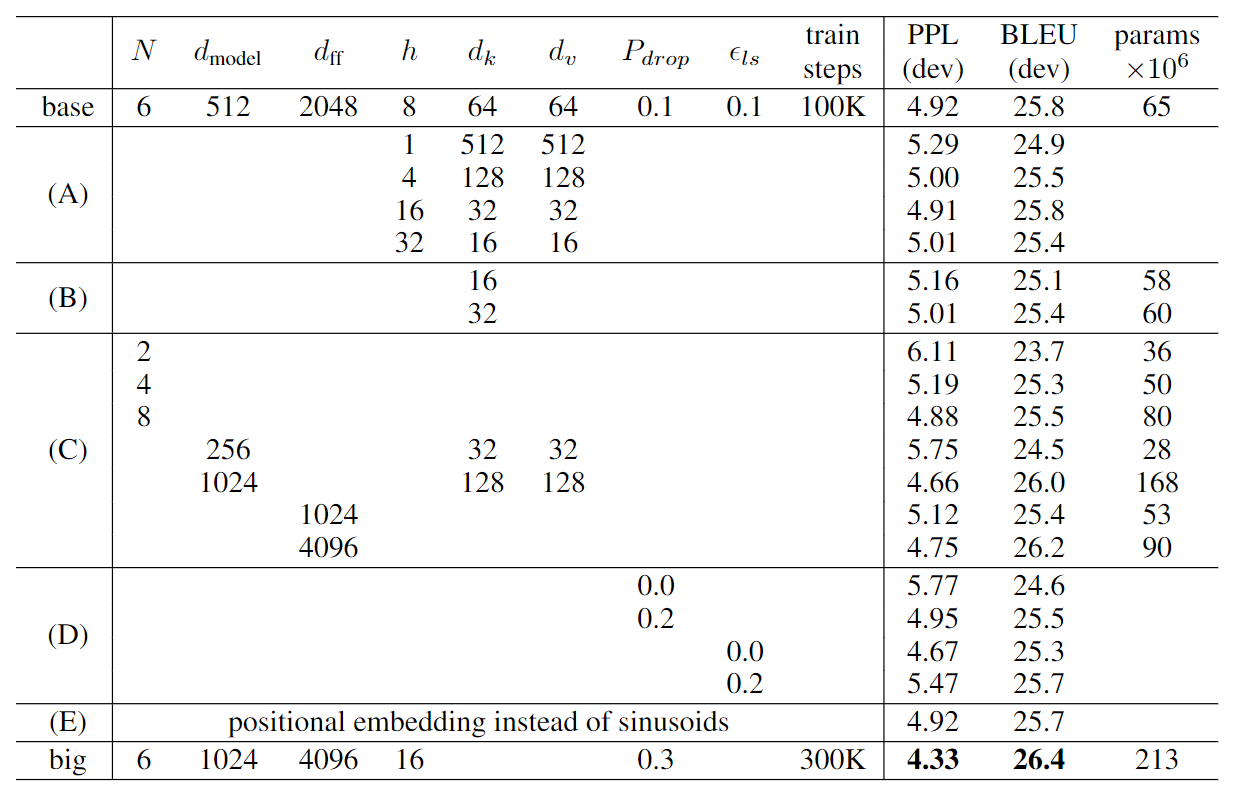
(A)를 보면, h=1, h=32가 base일때보다, BLEU 스코어가 떨어진 것을 볼 수 있다. 이를 통해, 너무 적거나, 많은 것 헤드는 오히려 성능을 저하시킨다는 결과를 얻을 수 있다.
(B)를 보면, Query, Key의 차원인 dk의 크기가 작아지는 것은 모델의 성능을 떨어트린다는 것을 알 수 있다. 이를 통해, Query와 Key에 대한 Score를 계산할 때, 내적보다 더 정교한 함수가 이득이 될 수 있을 것이란걸 파악해 볼 수 있다.
(C), (D)를 보면, 예상했듯이 큰 모델이 더 좋은 성능을 낸다는 것을 알 수 있다. 또한 Dropout이 오버피팅을 방지하는데, 도움이 되는 것을 확인할 수 있다.
정리하는 글
지금은 너무 널리 알려졌고, 이젠 많이 유명해진 Transformer가 발표된 논문이다. 구조를 보면, 전적으로 Attention형태만 사용하고 있고, 시퀀스의 병렬처리와 계산효율성을 크게 개선한 점이 눈에 띈다. 그러니까 많은 장점으로, 아직도 Attention은 전부 인가 싶기도 하고... 단점이나, 개선할 수 있는 부분은 없을까 고민해 보게 된다.
고민하기
1. 시퀀스의 길이(N)가 커지면, 연산량이 크게 늘어난다.
다른 모델 구조와 다르게 Self-Attention은 시퀀스의 모든 쌍에 대해서 연산을 수행한다. 따라서 시퀀스의 길이가 증가할수록, 연산량이 크게 늘어난다는 문제점이 있다.
2. Positional Encoding에 대한 확장
논문에서 제시한 방법은 sin, cos을 Positional Encoding에 사용함으로, 학습을 하지 않고, 위치에 대한 정보를 주입할 수 있었다. 하지만 이 것을 더 개선할 방법은 없을까?
이 논문에서 제시된 Transformer구조를 활용해서, 다양한 파생 모델들이 등장했고 현재까지도 발전하고 있다. 아직까지는 주류가 되는 구조이지만, 최근 Mamba등 SSM기반의 모델구조들이 등장하고 있다. 이후, 발전의 흐름은 어느 방향으로 흐를지 모르겠지만, 나도 흐름을 잘 따라가야 할 것 같다..
'딥러닝(Deep Learning) > 논문 리뷰' 카테고리의 다른 글
| ModernBERT : Smarter, Better, Faster, Longer(더 똑똑하게, 좋게, 빠르게, 길게) (0) | 2024.12.26 |
|---|---|
| GSM-Symbolic : 애플의 새로운 수학 벤치마크 제안 (3) | 2024.11.09 |
| TODO: 23.12.29 Updated (0) | 2023.12.30 |