목차
개요
갑자기 HF에 등장한, ModerBERT에 대해서 짧게 정리해보도록 한다.
다프트펑크가 생각나는 논문 제목
Encoder Model은 정보 탐색에서 특히 인기있다. 최근 몇년동안 LLM이 주목받으면서, Encoder Model을 이용한 RAG, NER같은 Task에 대한 새로운 관심도 불러일으켰다.
하지만, 이러한 파이프라인에 아직도 백본으로 기존의 BERT모델(마지막 경험으론, DeBERTa를 아주 많이 사용하는 것 같았다.)을 사용하는 오래된 모델에 의존하고 있다. 이건 몇가지 문제가 있는데,
- 시퀀스 길이가 512토큰으로 제한된 것
- Vocab 크기
- 하위 작업 성능, 계산 효율적 측면에서 비효율적인 모델 설계
- Suboptimal한 모델 디자인
- 훈련 데이터가 제한적이고, 특정 도메인에 한정(특히, 코드 데이터의 부족)되어 있으며, 최근 사건에 대한 지식의 부족
ModernBERT
ModernBERT는 현대화된 Encoder-Only 모델로, down-stream 성능과 효율을 증가하기 위해(특히, 긴 시퀀스 길이), 발전된 구조를 사용했다. 또한, Encoder-Only 모델을 Code 데이터가 포함된 2 trillion tokens의 더 큰 데이터로 훈련했다.
논문 리뷰는 아니기에, 학습 방법과 데이터셋, 결과에 대해서 짧게 메모형식으로 작성해보겠다.
학습 방법
- linear 레이어에서 더 많은 수의 파라미터를 사용하기 위해, 전체 linear 레이어(마지막 decoder linear 제외)와 Layer Norms에서, bias를 제거했다.
- RoPE(Rotary Positional Embeddings)를 사용했다.
- Embedding Layer이후에 LayerNorm을 사용하는, pre-normalization 블락을 사용.(중복을 피하기 위해, 처음 Attention Layer에서는 LayerNorm을 제거)
- Activation으로 GeGLU를 사용.

효율성 발전시키기
- Global Attention(매 3번째 레이어의 RoPE theta160,000)과 Local Sliding window Attention(나머지 RoPE theta 10,000, 128토큰 슬라이딩 윈도우)을 번갈아 가면서 사용
- Padding토큰을 제거, 미니배치의 모든 시퀀스를 단일로 연결하여 하나의 배치로 처리
- Flash Attention 사용
- torch.compile 사용
- 동일 파라미터 수에서, 추론 지연이 없도록 다양한 소규모의 제거실험을 통해 Deep&Narrow한 모델 설계.
모델 훈련
데이터
영어기반의 웹문서, 코드, 과학지 등 다양한 데이터 출처에서 2조개의 토큰으로 훈련
토크나이저
- 기존 BERT 토크나이저가 아닌, 현대의 BPE 토크나이저인 OLMo 토크나이저의 수정본을 사용. 이는 코드 관련 작업에서 더 좋은 토큰 효율성과 성능을 제공한다. 또한 원래 BERT 모델과 동일한 Special Token([CLS], [SEP] 등)과 템플릿을 사용하여 호환성을 쉽게함.
- 최적의 GPU활용을 보장하기 위해서, 64의 배수인 Vocab갯수를 50,368로 설정하고, downstream 지원을 위한 83개의 사용하지 않는 토큰을 포함.
Sequence Packing
언패딩으로 인한 높은 미니배치 크기의 변동을 피하기 위해서, 그리디 알고리즘을 사용하여 99퍼센트의 이상의 효율성을 가진 Sequence Packing을 적용함. 이는 배치 크기의 일정함을 보장한다.
모델 훈련 설정
MLM(Masked Language Modeling)
MosaicBERT에서 사용한 MLM을 따른다.
- 성능 개선향상에 도움이 되지 않는, 큰 오버헤드를 제공하는 Next-Sentence Prediction Objective를 제거한다.
- masking 비율을 sub-optimal한 결과인 기존의 15% 대신, 30%를 사용한다.
Optimizer
파라미터별 학습률 조절하는 업데이트 클리핑을 적용하는 Adafactor-style을 추가하는 방법으로 AdamW을 발전시킨, StableAdamW 옵티마이저를 사용한다.
Learning Rate Schedule
Pre-Train 과정 중에는 수정된 trapezoidal(사다리꼴형태의) LR 스케쥴을 사용. trapezoidal 스케줄러는, Learning Rate을 짧은 Warm-Up -> 긴 Constant -> 짧은 Anneal 과정을 가진다. 또한, 마지막 감소 과정에서 선형이나 코사인 형태가 아닌, 을 사용한다.(이게 더 성능이 좋았다고 한다.)

- ModernBERT-BASE : 3billion Token Warm-Up -> 1.7trillion token constant LR of 8e-4
- ModernBERT-LARGE : 2billion Token Warm-Up -> 900billion token constant LR of 5e-4 -> 수천억개의 토큰을 5e-4로 손실을 안정화 -> 나머지 800billion Token은 LR 5e-5로 다시 시작
Batch Size Schedule
- ModernBERT-BASE : 50billion Token에서 768->4,608로 증가하는 Warm-Up
- ModernBERT-LARGE : 10billion Token에서 448->4,928로 증가하는 Warm-Up
Weight 초기화, 타일링
- ModernBERT-BASE : Megatron 초기화에서 사용한 랜덤 Weights를 사용-> 기본적으로
N(0, 0.02)의 정규분포를 따름. Residual 레이어 직전에 가중치는\frac{1}{2N}로 조정 한다.(은 self-attention, MLP블록의 수) - ModernBERT-LARGE : Phi Model의 과정을 따름. Pre-Train된 ModerBERT-BASE모델의 가중치를 중간에 배치하여 초기화하고, wraparound. 이를 통해, 초기 훈련을 빠르게 진행할 수 있었음.
Context Length 확장
1.7trillion token에 대해서 1,024의 시퀀스 길이와 RoPE theta 10,000으로 학습한 후, Context Length를 8,192 토큰으로 늘리기 위해, Global Attention Layer의 RoPE theta를 160,000로 증가시키고, 300billion token을 추가로 학습했다.
Downstream 성능
통상적으로, BASE 모델은 150million 파라미터 수를 갖고, 비교모델로는 "BERT-base", "DeBERTa-v3-base", "RoBERTa-base", 8,192의 컨텍스트 길이를 갖는 "NomicBERT", "GTE-en-MLM-base"모델이 있다.
LARGE 모델은 300million ~ 500million 파라미터 수를 갖고, "BERT-large-uncased", "DeBERTa-v3-large", "RoBERTa-large", "GTE-en-MLM-large"가 있다.
평가 셋팅
Natural Language Understanding(NLU)
- GLUE 벤치마크
Text Retrieval(Text 검색)
다양한 작업과 도메인에서의 검색 성능을 평가하기 위해, BEIR 벤치마크의 서브 데이터셋을 사용한다.
- BEIR 벤치마크 : NFCorpus, SciFact, TREC-Covid, FiQA, ArguAna, Climate-FEVER, DBPedia, FEVER, HotpotQA, MSMARCO, NQ, Quora, SciDocs, Touche2020, CQADupstack
검색 작업에는 단일 벡터를 검색에 사용하는 DPR, 여러개의 벡터를 이용하는 ColBERT 구조를 사용한다.
Single Vector - DPR
MS-MARCO with Hard Negatives 의 1.25M 샘플을 배치사이즈 16으로 Learning Rate를 5%동안 Warm-Up하고, Sentence-transformer를 이용해서 학습을 진행.
Multi Vector - ColBERT
모든 개별 토큰의 벡터로 표현하여, Query와 Document간의 MaxSim 연산을 통해 계산. JaCol-BERTv2.5의 훈련설정을 사용하고, 배치 크기는 16, Learning Rate는 5%로 Warm-Up. MS-MARCO의 810k샘플을 통해 학습. Teacher와 Student 모델의 KL-Divergence를 통해 Knoledge Distill을 진행.
Long-Context Text Retrieval
ModernBERT는 8,192 컨텍스트 길이를 지원해서, 기존 대부분의 Encoder에 비해서 Long Context에 대해 성능이 향상됐다. 하지만 Encoder-Only 모델에 대한 Long-Context 벤치마크가 적고, 대부분의 벤치마크(Needle-in-a-haystack, RULER 같은)는 Generation 작업에 맞춰져있다.
이러한 한계로, 200,000개 이상의 긴 문서로 구성된 MLDR의 영어 데이터셋에서 향상된 Long-Context 성능을 아래의 세가지 설정을 통해서 평가한다.
- Single Vector - Out of Domain : 위에서 언급한 Short-Context의 MS-MARCO로 학습된 DPR모델을 추가 파인튜닝 없이, Long-Context MLDR에 대해 평가.
- Single Vector - In Domain : MS-MARCO로 학습된 동일한 모델을, Long-Context MLDR을 이용해 추가 파인튜닝하고 평가.
- Multi Vector - Out of Domain : ColBERT모델은 Token-Level의 MaxSim으로, 추가 미세 조정없이 Long-Context에 일반화할 수 있음. 따라서, 최선의 체크포인트를 이용해서 평가.
Code Retrieval
ModernBERT는 Code에 대해 Pre-Train을 진행하고, Code-Aware 토크나이저를 사용한다. 따라서, 코드 검색능력에 대한 벤치마크를 CodeSearchNet과, StackOverflow-QA를 통해서 측정한다.
평가는 CoIR(CodeIR)프레임워크를 이용해서, Single Vector Retrieval수행. 모든 모델은 Best Hyper-Parameter를 재사용.
평가 결과

예상한대로, ModernBERT가 Base, Large모델 규모에 대해, 전체 작업에서 가장 좋은 성능을 보인다.
Short-Context Retrieval부문인 BEIR벤치마크에서, Single-Vector(DPR), Multi-Vector(ColBERT) 셋팅 양쪽 다 최근 모델인 NomicBERT, GTE-en-MLM을 포함해도 더 좋은 결과를 보였다. DPR셋팅에서 ModernBERT-Base는 GTE-en-MLM-Base에 대해서, 근소하게 우세한 결과를 보였지만, Large에서는 더 적은 파라미터(395M vs. 435M)임에도 더 좋은 성능을 냈다.
Long-Context Retrieval에서는 NomicBERT는 DPR, ColBERT 모두 능가하지만, GTE-en-MLM에서는 DPR 에서는 Out-Of-Domain에서는 성능이 크게 안좋고, In-Domain에서는 0.4정도의 차이로 근소하다. 이유를 생각해보자면, Single Vector - OOD 평가 셋팅은, MS-MARCO의 Short-Context로 학습하고, Long-Context에 대한 추가적인 학습을 수행하지 않았다. 그렇기에 성능 차이가 많이 나는 것이고, Single Vector-In Domain 평가에서는 Long-Context인 MLDR의 학습 데이터셋을 이용해서, 추가 학습을 진행했다. 따라서 결과가 별로 차이가 나지 않는 것으로 예상된다.
MLDR에 대한 추가 미세 조정이 없었음에도 불구하고, ColBERT셋팅에서 Long-Context를 지원하는 다른 모델들(NomicBERT, GTE-en-MLM)도 40 nDCG@10 를 넘는 발전된 좋은 성능을 보인다. 따라서, ColBERT구조가 Long-Context Retrieval에 적합한 것으로 보인다. 더 나아가, ModernBERT는 Base, Large 규모의 모델 모두 최소 9 nDCG@10 점 이상 더 향상된 결과를 내어, 다른 모델들보다 우수한 결과를 보여준다.
아마 같은 생각을 하는 사람이 있을 수 있겠지만, 왜 Multi Vecotr - In Domain에 대한 학습 결과는 측정하지 않은걸까? 해당 아티클에 따라, Token-Level MaxSim을 사용하면, 추가 학습없이도 일반화를 할 수 있다했기 때문인데, 학습을 했을 때의 적용한 결과도 올려주면 좋았을 것 같다.
Natural Language Understanding에는 GLUE를 사용한다. Base규모에서는 가장 뛰어나지만, Large에서는 DeBERTa를 이기지 못했다. 하지만, 모델의 파라미터 수가 더 적고, 추론 효율성에서 tokens-per-second가 거의 두배로 뛰어났다.
Code 에서는 Base, Large 규모 모두 뛰어났다. 아마 Programming Data가 섞인 데이터셋으로 학습을 진행했기 때문이 아닐까 추측한다. 다른 Task에서도 잘하는데, Code에 대한 이해도 잘한다?(장하다 내새끼.. 저자가 아주 만족스러워하는 어투가 논문에서 엄청 보인다.. ㅋㅋㅋ)
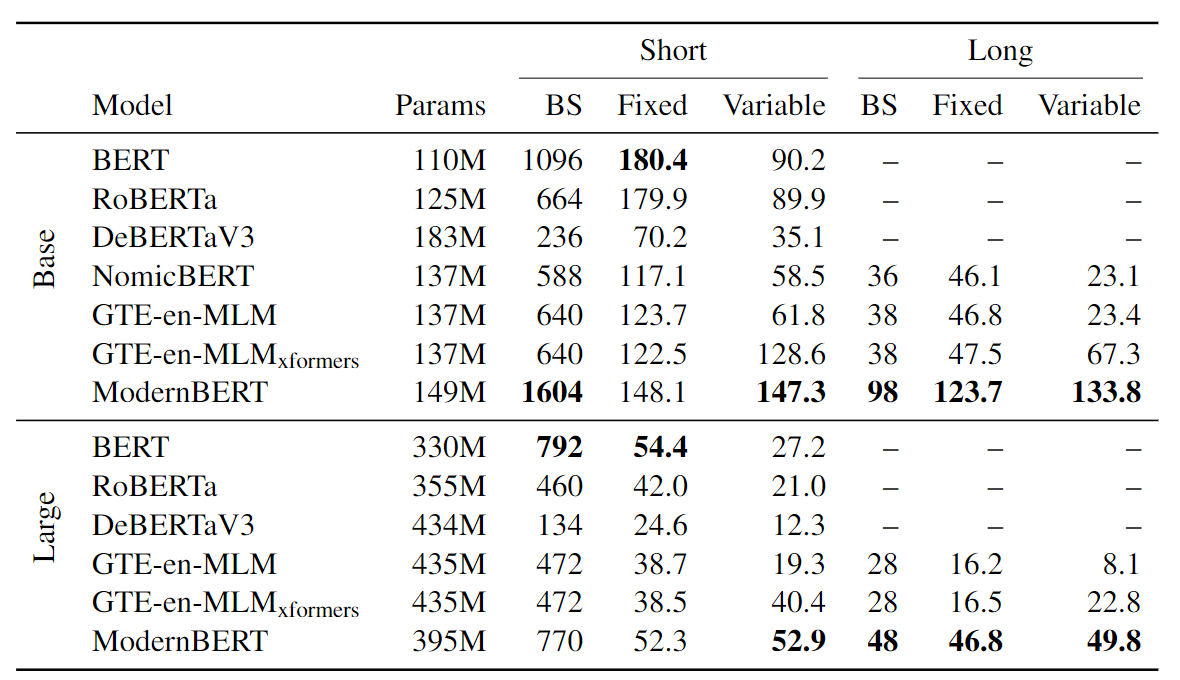
효율성 측정에서는 8192개의 문서로 구성된 각각 4개의 합성 데이터셋을 만들었다. Short-Fix(고정된 짧은 길이 / 512토큰), Short-Variable(가변 짧은 길이 / 256토큰 중심의 정규분포), Long-Fix(고정된 긴 길이 / 8,192토큰), Long-Variable(가변 긴 길이 / 4,096토큰 중심의 정규분포). 가변 길이는 unpadding의 영향을 고려하기 위해서, 고안되었다. 효율성 측정의 결과는 단일 RTX4090에서 10번의 실행동안 평균을 낸 process token-per-second 결과이다.
Short Context 처리에서는 BERT와 RoBERTa보다는 느리지만, 다른 최신 모델들보다는 빨랐다. Long Context처리에서는 다른 모든 모델보다 Base, Large규모 모두 2.65~3배이상 빠른 모습을 보인다.
Variable 데이터 처리에서는 unpadding의 결과로 GTE-en-MLM과 ModernBERT가 모두 압도적으로 빨랐다. 하지만, Local Attention 덕분에, Long Context에서는 큰 차이로 ModernBERT가 GTE-en-MLM을 압도한다.
이번엔 메모리 효율성을 보자. Base규모에서는, Short, Long Context 모두 다른 모델들보다 Batch Size를 두배이상 처리할 수 있다. Large규모에서는 Short-Context에서는 약간 떨어지는 모습을 보이지만, Long-Context에서는 60%이상 Batch Size를 처리할 수 있다.
결론

ModernBERT는 GeGLU, RoPE, local-global attention, unpadding, Code mixtures 등의 최근 발전된 현대 기술로 Encoder-Only 모델의 성능과 효율성 모두 개선한 모델이다. 최근 Generative Model이 대세로 대부분의 NLP 연구는 LLM을 훈련하는 것, 생성 전략에 치중되어 있었는데, Encoder-Only 모델의 개선으로 RAG 과정에서도 큰 도움을 줄 수 있을 것으로 예상된다.
나도 저번 Kaggle - LLM Science Exam대회를 참여하며, RAG 전략을 사용했었는데 그 때도 DeBERTa를 사용한 결과가 좋게 나왔었던 것으로 기억한다. 하지만 처리하는 시간이 너무 오래 걸려서, 다른 전략을 찾아봐야했던 것으로 기억한다. ModernBERT는 현대의 기술로 처리시간을 크게 줄이고, Long-Context처리를 가능하게 하고, 성능을 상당히 높여 Encoder-Only 모델의 새로운 혁신을 가져왔다.
이 모델로 한국어를 지원하는 새로운 모델을 학습해보면서, 한국어 성능 향상을 가져올 수 있는지 검증해볼 수도 있겠지만, 논문을 다 읽어보면서 현대 NLP 기술의 트렌드에 대해서 정리하는 기회가 되었다. 따라서 본문에서 언급된 세부기술들에 대해서도, 모르는 것도 많이 있어서 하나씩 전체적으로 살펴봐야겠다. 끝.
(짧은 메모로, 학습전략이나 데이터셋에 대해 정리하려 했는데 어쩌다보니 다 읽으면서 정리했다..)
'딥러닝(Deep Learning) > 논문 리뷰' 카테고리의 다른 글
| Attention Is All You Need : 아직도 어텐션이 전부야? (0) | 2024.12.10 |
|---|---|
| GSM-Symbolic : 애플의 새로운 수학 벤치마크 제안 (3) | 2024.11.09 |
| TODO: 23.12.29 Updated (0) | 2023.12.30 |